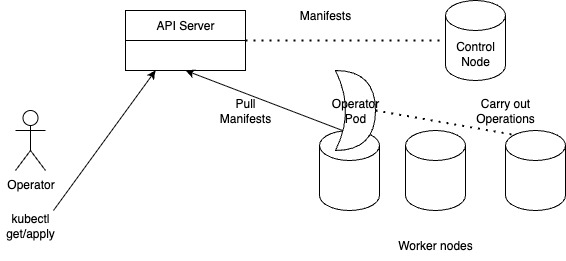
Anatomy of a Kubernetes Operator
So you have decided to tackle the belly of the beast, namely to learn kubernetes inside out. How then should you start ? By implementing a Custom Operator from scratch, that’s right !
Why? Because it touches many aspects of Kubernetes. An operator builds on top of the fundamental primitives provided by Kubernetes itself: such as Deployments, Service Accounts etc. By learning how to deploy an Operator I got a really good grounding on how to work with Kubernetes and and was able to get very comfortable with it.
What does an Operator do ? Well, it can do a lot. You can deploy custom resources like Database Pods, Job system Pods etc, or even implement networking policies drivers and Storage Drivers for using various new kinds of storage devices. In this exercise, I am going to do something a bit simpler: namely implement a way to perform image manipulation using Kubernetes Objects.
We will implement an Object whose specification looks like this to rotate an image by 90 degrees:
apiVersion: imaging.example.com/v1
kind: ImageProcessor
metadata:
name: test-rotate
spec:
data: /9j/4AAQSkZJRgABAQEAYABgAAD/2wBDAAcFBQYFBAcGBQYIBwcIChELCgkJChUPEAwRGBUaGRgVGBcbHichGx0lHRcYIi4iJSgpKywrGiAvMy8qMicqKyr/...
operation: "rotate"
params:
angle: 90The data is a base64 encoding of the contents of a JPEG file. Once you apply this spec to the Kubernetes Cluster, our operator will pick up this spec and process the image based on the operation and the params provided to it. Before and during the operator picking up the resource, it sets a spec.status.phase to denote the status of the operation. The phase can be one of
pending- we are still processing the imagecomplete- we are done processing the image. thespec.status.resultcontains the base64 encoded result of applying the operation to the provided imagefailed- we ran into an error when processing the image andresultis probably not set.
To be able to submit an object like this to our cluster, we need the following pieces of machinery:
- A CustomResourceDefinition - From the name we can infer that this entity defines a custom resource. We must tell Kubernetes what are the fields that must be present in the definition, the “group” it belongs to and how can a user list one or more of such resources using
kubectl get.
The CustomResourceDefinition for our Image Processor looks like the following
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: imageprocessors.imaging.example.com
spec:
group: imaging.example.com
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
data:
type: string
operation:
type: string
params:
type: object
x-kubernetes-preserve-unknown-fields: true
required:
- data
- operation
status:
type: object
properties:
phase:
type: string
result:
type: string
message:
type: string
subresources:
status: {}
additionalPrinterColumns:
- name: Operation
type: string
jsonPath: .spec.operation
- name: Phase
type: string
jsonPath: .status.phase
- name: Age
type: date
jsonPath: .metadata.creationTimestamp
scope: Namespaced
names:
plural: imageprocessors
singular: imageprocessor
kind: ImageProcessorWe can group Resources using a unique group name (in our case: imaging.example.com). Grouping allows a sort of “namespacing” (not to be confused with Kubernetes namespaces) of entities. This allows vendors to provide Resources that might have similar names but uniquely identifiable by the combo of group + Resource Kind. The default kubernetes resources such as Pods, Deployments etc have the group ""
In the line: scope: Namespaced, we tell Kubernetes that our Resources are scoped at the namespace level and in the following lines, we tell the Kubernetes API server what names can kubectl use to fetch a list of singular kubectl get imageprocessor resource-name or multiple resources kubectl get imageprocessors.
The lines before additionalPrinterColumns define the output columns of the response from the api-server for kubectl get calls. By default, kubectl get imageprocessor will list out the name of the Resource, the name Operation, the phase of the operation and the creation time of the Resource.
The schema of our resource defines is defined by 2 objects spec and status with the following key for spec
data- the base64 encoded jpeg image data 2operation- an enum of either “rotate”, “translate” or “scale”params- parameters of the operation, arbitrary subject to the operation we want to perform
Now that we have a Resource Definition, we must now add the piece of machinery that will “act” on this resource when it its manifest is submitted to the Cluster.
When you create a Kubernetes Pod/Deployment (or any other resource), the request is handled by the api-server (kubectl is basically a wrapper over HTTP calls to the api-server). The api-server accepts (or rejects) manifests, stores them and for custom resources, a running Pod(s) gets the manifest from the api-server and carries out the appropriate action. This is the Operator pattern, where you extend the functionality of Kubernetes by running Pods that implement the new functionality. Clever, isn’t it ?
How does your Operator Pod know when a user has created a new manifest ?
Your operator has to know when a user has requested for a new Custom Resource. It does that by subscribing to the Watch endpoint of the API Server which sort of delivers a event log of changes on resources to your controller. Your controller can then choose to make changes (or ignore them) corresponding to the resources. In our case, when a user requests a new image operation with a payload, we first update the status of the operation as pending, perform the operation and if it succeeds, update status to success and set the result of the operation to the transformed image
Before our controller pod is capable of doing that, we need to authorize our Controller’s Pods to be able to watch for the resources it cares about. To do, we create a ClusterRole with the permissions to perform certain operations on certain kinds of resources
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: image-processor-operator
rules:
- apiGroups: ["imaging.example.com"]
resources: ["imageprocessors"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: ["imaging.example.com"]
resources: ["imageprocessors/status"]
verbs: ["get", "update", "patch"]The image-processor-operator role provides permissions to a resources of kind imageprocessors in the apiGroup imaging.example.com. This corresponds to the apiVersion and Kind
apiVersion: imaging.example.com/v1
kind: ImageProcessorin our Resource definition.
A ClusterRole only defines the permissions. We need to associate it with an Identity that can be attached to Pods to enable Pods to perform operations in runtime.
This Identity is provided by a ServiceAccount and we bind the ClusterRole to it with a ClusterRoleBinding
(If you find this confusing, think of it this way: the office has 2 Admins: Roger and Moore. Both the admins have the keys to the coffee machine and can lock up the machines if needed. Roger or Moore can quit tomorrow and the company can hire McDonald as the new Admin. The Role Admin gives you power over the coffee machine, but the identities of the people are Roger , Moore or William who are given the role of Admin in the company)
apiVersion: v1
kind: ServiceAccount
metadata:
name: image-processor-operator
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: image-processor-operator
rules:
- apiGroups: ["imaging.example.com"]
resources: ["imageprocessors"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: ["imaging.example.com"]
resources: ["imageprocessors/status"]
verbs: ["get", "update", "patch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: image-processor-operator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: image-processor-operator
subjects:
- kind: ServiceAccount
name: image-processor-operator
namespace: defaultThe last step is to deploy our controller application. We make use of Kubernetes native Deployment to run multiple replicas of our Controller’s Pod. All of the Controller’s Pods have the image-processor-operator Identity (ServiceAccount) attached to them which will give them the credentials at runtime to be able to subscribe to the Kubernetes api-server’s Watch API.
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-processor-operator
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: image-processor-operator
template:
metadata:
labels:
app: image-processor-operator
spec:
serviceAccountName: image-processor-operator
containers:
- name: manager
image: image-processor-operator:latest
imagePullPolicy: Never
ports:
- containerPort: 8080
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 100m
memory: 128MiContainer Image
I tested this out using a minikube setup on my local machine to simulate a Kubernetes Cluster locally. One can config docker to store the images with minikube using eval $(minikube docker-env) which populates your environment with variables to push the images to the minikube image repo and building the image
docker build -t image-processor-operator:latest . will ensure that the image is available for deployments on your local minkube.
Application code.
This part is interesting. I am no Rust guy. I tried to implement this initially in Go (not a Go guy either) using kube-builder, but never in my life did I think that I would find a Go framework more verbose and unfriendly than Spring Boot. So much boilerplate, so much meta-programming via annotations and directives, that heck it was easier to vibe code this with the Rust kube-rs library than it was to figure out what kubebuilder was doing ! Claude was near perfect, spitting out the code for my Controller in less than a few minutes. I had to compile, paste the error message a few times back and forth to get it right, but I got things done in a few minutes that I initially assumed would take me the better part of a month or more ! Yeah that’s how good LLMs have gotten today.
Deploying this to your Cluster
You have a CRD, a Deployment, a Service Account and the corresponding Roles and Role bindings. You could either install them manually like a hobbyist or package them into a Helm chart that can be then versioned and managed. I packed all of the needed manifests into a helm template folder in my repo. Installing this into my minikube cluster was as simple as running
$ helm install image-processor-operator-r1 image-processor-operator
NAME: image-processor-operator-r1
LAST DEPLOYED: Sat Jul 19 00:54:20 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: NoneI would suggesting referring to this resource for a good tutorial on how to package your Helm templates into an archive that can be uploaded and shared with others to be installed on Kubernetes Clusters
Processing images
The last step is to actually create our processing jobs. I created a manifest with the image and the operation in the file item.yaml in my repo and applied the manifest
~/personal/algorithms/imageoperatorrs on master! ⌚ 0:54:29
$ k apply -f item.yaml
imageprocessor.imaging.example.com/test-rotate created
~/personal/algorithms/imageoperatorrs on master! ⌚ 0:54:34
$ k get imageprocessors
NAME OPERATION PHASE AGE
test-rotate rotate Complete 14sand Voila, our image is processed! The Phase value of Complete indicates that our processing is done successfully and we can extract the rotated image from the status of the processing job
~/personal/algorithms/imageoperatorrs on master! ⌚ 1:02:27
$ kubectl get imageprocessors test-rotate -o jsonpath='{.status.result}' | base64 -d > out.jpeg
~/personal/algorithms/imageoperatorrs on master! ⌚ 1:10:33
$ open out.jpegConclusion
Great systems offer a small number of robustly designed fundamental abstractions and then allow the user to build complex functionality based on the interaction of those abstractions. The greatest example of this is UNIX: everything is a file, Processes, one-way information passing via Pipes and the file system as a tree.
Similarly we built complex functionality using some basic primitives: our image processors are nothing but Pods themselves getting manifests from the Kubernetes API Server. We gave our Pods permissions to create and update manifests using Cluster Roles and bound them to Service Accounts. For making changes to the Kubernetes Worker Nodes itself to support say newer harddrives or storing data into blob stores we could run our Operator’s Pod’s containers with a privileged security context thus allow it modify the worker nodes itself.
Kubernetes is a complex system. As an application Developer, I experienced immense frustration trying to get my deployments working as intended on Kubernetes. As a Kubernetes Operator, I understand the need for much of the complexity (ofcourse there remains scope to simplify many things), especially around governance and compliance to ensure that users aren’t really trashing the shared resources of nodes and degrading the performance of workloads of other users.
Kubernetes solves a lot of problems for large organizations around right-sizing and governance/monitoring. Setup right, it can make the infra experience for Application developers a lot simpler and reduce the operational burden. But it is also important to have the right expectations on how long it will take to get comfortable with it. If you are learning to use Kubernetes, do not expect to learn and get comfortable with it in a matter of days, or even weeks. Your journey will be smoother and less traumatizing once you set realistic expectations for yourself and try to figure out what problem is being solved and why before jumping into the solution.