Thinking in CUDA (or what I learnt in April 2025)
CUDA
I finally fulfilled a decade long dream of learning to do GPU compute by finally setting aside time to learn CUDA. Why didn’t I do it earlier when it had been a life long ambition ? I gave myself many excuses: tried my hand at building web apps, APIs, DevOps. The ZIRP era afforded a lot of opportunities to make money and ML was not something I was interested in the pre-LLM era. Spending a lot of time doing different things gave me the clarity on what really motived me towards computers in the first place: tinkering with hardware and low level primitives and figuring out how to build make them go brrr
So how do you program a GPU ?
You would have heard of the word kernel thrown around a lot in the context of GPUs. Kernels are a fancy way of saying functions that are executed on the GPU.
Before kernels, there were shaders. A shader is a function (like a kernel), written in a shading language like GLSL or HLSL. These shaders were used to program the hardware in a GPU to compute vertexes of shapes (mostly triangles) and the colour of output pixels on a screen. The shaders that computed the vertexes and the colour of output pixels are called vertex shaders and fragment shaders respectively.
The syntax of a shading language is similar to C
attribute vec4 vertexPosition;
uniform mat4 modelMatrix;
uniform mat4 viewMatrix;
uniform mat4 projectionMatrix;
void main() {
gl_Position = projectionMatrix * viewMatrix * modelMatrix * vertexPosition;
}Before the CUDA era, Graphics cards used a fixed-function pipeline architecture. These GPUs were designed with dedicated, hardwired circuits for specific graphics operations, rather than being programmable. The rendering pipeline followed a fixed sequence of operations that couldn’t be modified by developers:
- Vertex processing (transformations, lighting)
- Rasterization (converting vertices to fragments/pixels)
- Fragment processing (texturing, coloring)
- Output operations (blending, z-buffering)
With the Nvidia 8800GTX, NVIDIA introduced Unified Shaders, hardware that could carry out any of the operations supported by the GPU.
Unified Shaders meant that the GPU could be used for general purpose computing as well as graphics processing.
CUDA is a software ecosystem that allowed programmers to write general purpose kernels that could be executed on the GPU. The general purpose meant pretty much anything : image processing, video processing, 3d rendering, scientific computing and the most important one of all today : machine learning. There are even usecases where GPUs were used to accelerate queries on databases using a GPU implementation of a B-Tree
Thinking in terms of Ops per Byte
The RTX 4090 has GDDR6X memory that can roughly support 1TB/s of bandwidth (roughly it can transfer 1TB/s of data in and out of the GPU). The RTX 4090 has a peak FP32 performance of 82 Teraflops.
To add 2 FP32s numbers and store the result, we need to load 2 4byte FP32 values and store 1 4byte FP32 value. This translates to around 12 bytes of memory bandwidth per operation. To support 82 Teraflops, we need 82 Teraflops * 12 = 984 TB/S of bandwidth which is ~1000x what our memory is capable of supporting !
Even with HBM3, which is capable of 3-5 TB/s of second, we still get only 246-410 TB/s which is still not sufficient to feed our GPU with data fast enough to sustain peak performance.
Therefore when coming up with algorithms to run on the GPU, it makes sense to think in terms of Flops/Byte, that is,the number of operations our kernels perform for every byte of memory that needs to be loaded or stored from/to the global memory. The fewer the loads/stores, the faster the code can run.
Each Streaming Multiprocessor (CPU core of sorts) has a certain amount of shared memory (think of it as the L1/L2 cache equivalent) that can be used to share memory between threads in a block. Fast kernels try to load reused data elements from the global memory into the shared memory and or the registers of each thread to amortize the cost of loading the data from the global memory.
Thinking in terms of output Threads
For programmers who have worked with multi-threading and multiprocessing on CPUs, launching 1024 threads or more feels like a lot. The average CPU on a laptop has anywhere between 4 to 12 cores and while threads aren’t as expensive as they used to be modern Operating System, they are still expensive enough and launching more than 2 threads per CPU core doesn’t add a lot of benefits.
In contrast GPUs are designed to handles 1000s of threads and the more work you can do per thread, the more you can get out of the GPU.
In the typical CPU matmul algorithm, you would have one thread that loads the matrix A, the matrix B, computes the elements of the Matrix C and writes the output.
On the GPU however, we launch threads per output index [i][j] and each threads will load and multiply elements of row i of matrix A and column j of matrix B.
Threads in a GPU are grouped into 1/2/3 dimensional blocks and blocks are grouped into a 1/2/3D grid. If we can load elements from A and B that are shared by all the threads in a block, then we amortize the cost of loading the elements from the GPU memory.
Tiled matrix multiplication does exactly this. It splits the length of the rows M into phase, and in each phase loads loads BLOCK_DIMxBLOCK_DIM elements of A and B. Each phase computes a partial sum of the output matrix C and by the time all the phases are complete, the output matrix C is computed. By loading only BLOCK_DIMxBLOCK_DIM elements of A and B in each phase, we make maximum use of the shared memory of each Thread Block and accelerated the matrix multiplication.
When thinking about tiled matrix multiplication, I tried to visualize the problem from the perspective of the output threads. If I am a thread C[i][j] in a block with BLOCK_DIM threads, how do I split the problem into phases ? And what elements of A and B do I load in each block ? In a CPU world, I would go from A and B -> C whereas this time, it helps to think of the problem as going from C -> A & B. GPU oriented programming needs a shift in perspective in-order to get good at it.
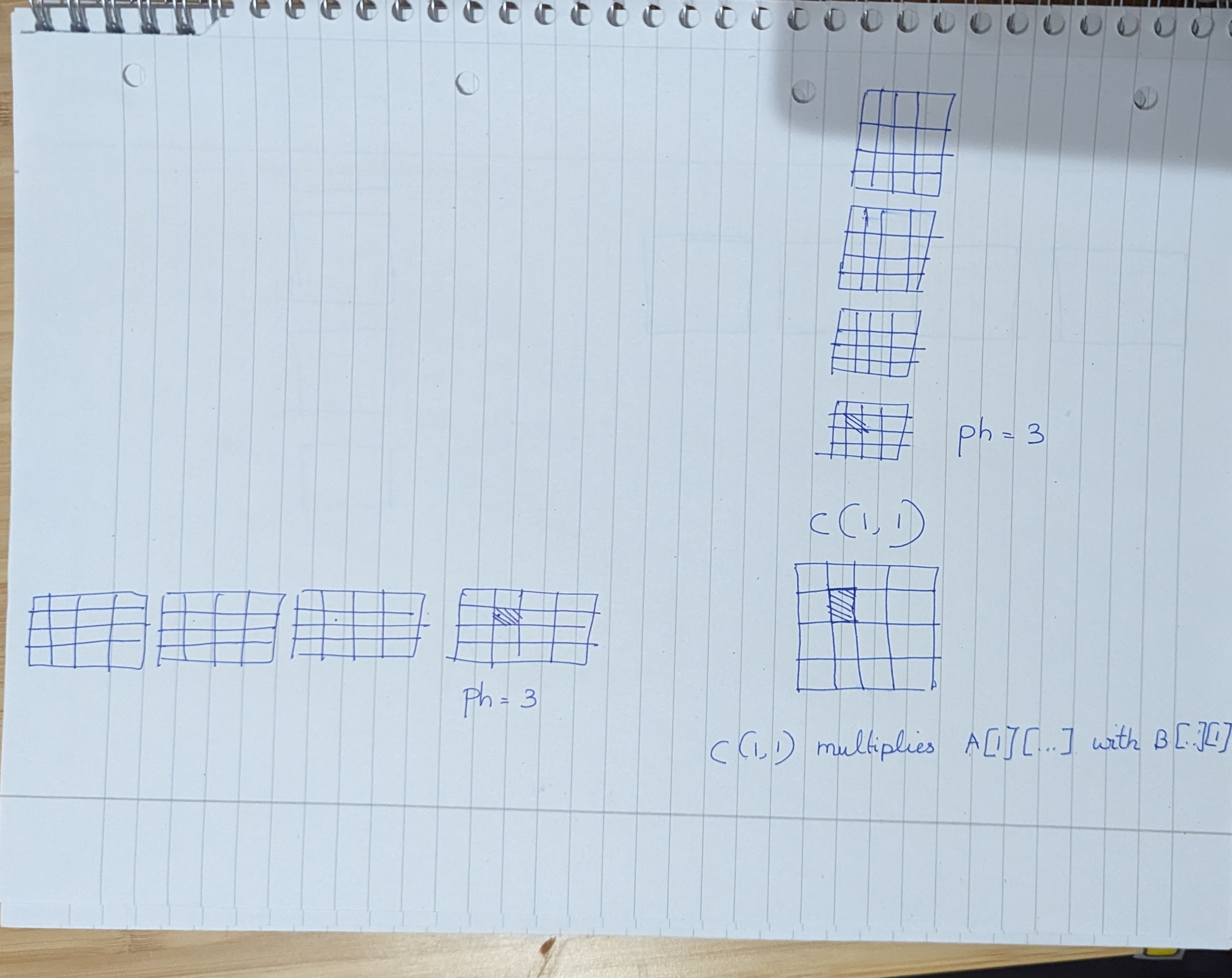
How am I learning CUDA ?
Practice
I use Tensara to practice writing CUDA kernels. Tensara is kinda like Leetcode, but for ML focused problems that are run on actual GPUs. There is also LeetGPU which has a smaller number of problem at the moment, but the Pro plan seems to offer better features, such as comparisons with other people’s solutions and getting better visibility into the performance of your kernels. One Tensara, when my code fails the tests(which it often does since Iam a total noob), it shows only a sample of the input indices that failed to match the expected output, which makes it hard to debug why it fails. Compilation errors however, show up with the exact line number and the location where the platform found an issue when compiling your code. I guess LeetGPU might be different/better (especially on the Pro plan, but I haven’t tried it out yet).
Both platforms seem to be sourcing the problem statments from KernelBench which is a collection of ML/GPU focused problems that for LLMs to try and solve, ranging from simple vector addition kernels to full blown architectures. It is definitely worth trying to ace all the problems in KernelBench to get really good at GPU programming and LLM architectures
Honourable mention: HipScript
HipScript is an absolutely cracked project written by the Developer Ben Schattinger to compile CUDA kernels to run them on the browser. It uses AMD’s HIP to translate CUDA code into code that can be run on CPUs or NVIDIA and even AMD GPUs ! The writeup on how it works is super awesome and I cannot describe in words the sheer respect I have for the developer’s ability and contribution !
Resources
The gold standard is still the Orange Book : Programming Massively Parallel Processors
The latest edition seems to relatively new (2020) and it teaches all the basic parallel programming patterns and each chapter teach a new technique (Tiled Mat Mul, Convolutions, Parallel Reduction etc) while showing how to make effective use of the hardware to improve performance.
One complaint I have with the book though is that it leaves a small but crucial part of running the algorithms: namely that of calculating the input and the output grid and block sizes. When splitting up an input array into blocks with X number of threads per block, you need to do some calcuations on the size of the grid and the size of each block. This ensures that you launch enough threads to cover each element in the output while optimzing for filing up the shared memory.
Calculating these values by yourself is a great exercise, but when you are in the middle of understanding kernel code and when you are struggling to calculating the thread index values in cases like OUT_DIM * blockIdx.x + threadIdx.x - FILTER_RADIUS, it can be a bit frustrating initially. I am trying this as an opportunity to sharpen my algorithm skills rather than complaining about the book however and help is online aplenty.
I hope someday this book is euologized like the Dragon Book for Compilers or TAOCP for algorithms.
Another book I have read (not fully, but a couple of chapters) is the Professional CUDA C Programming book. This one seems a bit more friendlier (the Orange book is also very friendly) and goes a bit more into the details of the CUDA API while the Orange book focuses itself only the parts of the CUDA API that is needed to write the kernels.
Next steps
These are just the initial steps into CUDA/GPU Programming. I was toying with the idea of buying a Jetson Orin or a Nano or a NVIDIA GPU enabled laptop, but seeing my storage box littered with a RPi 2, a RPi 4, A Vicharak Vaaman, I realized that I just love collecting toys and not really playing with them. Once I solve atleast 50% of the problems on Tensara, I believe it would be sign of me having committed sufficiently enough to justify such a purchase (or rent a GPU VM from vast.ai to run larger problems)
Paper readup : Fire-Flyer HPC
DeepSeek wrote a paper on their Fire-Flyer HPC Architecture for their GPU training systems. DeepSeek v3 caught the world in a storm with their SOTA benchmarks and more importantly the ability of the Chinese in squeezing every bit of performance out of their weakened hardware that they are forced to buy due to Sanctions. They wrote a custom AllReduce implementation: HFReduce that performed better than Nvidia’s NCCL communication libraries to reduce bandwidth usage in Multi-GPU setups. China is on-part with the Frontier labs in the USA in terms of ability and the paper illustrates just how capable they have become in designing software and HPC architectures. DeepSeek V3 “aha” moment, was not the result of the Chinese stealing American trade secrets but serious capabilities built over decades of research and development in HPC.